
Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. However, generated images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This comes with a downside, doing so limits their expressive power: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, and so the quality and diversity of generated images are severely affected, or (ii) the input is a hard-coded label, as opposed to free-form text, which limits the control over the generated images.
In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier.
We can show how the generated image changes over time as the embedding is modified iteratively.

Madagascar cat

Anna humingbird

Bullfrog

Spotted catbird
The class tokens trained with our method can also be used in different context, as shown in the images below. The three classes are from ImageNet, they are tiger cat, japanese spaniel, and beach wagon.

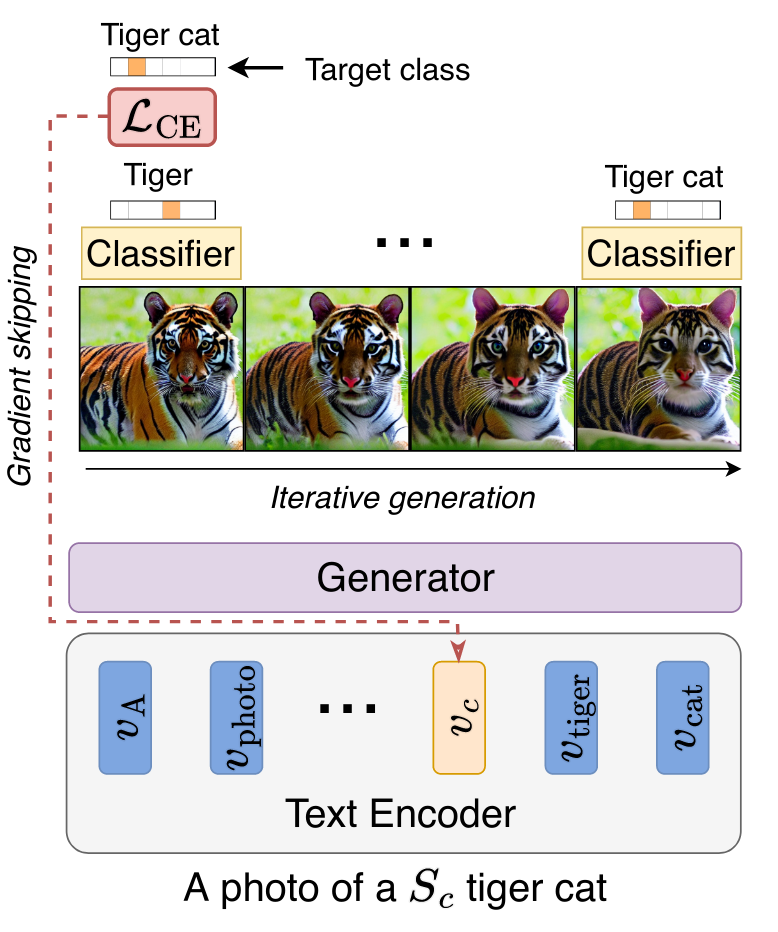
Our method works by adding a single new token to the input vocabulary of a text-to-image model. This token is then updated using a signal from a pretrained classifier. The classifier is used to guide the generation of images. Using gradient skipping, we more effectively update the embedding of the new token. We show that it is sufficient to backpropagate through the top iteration of the diffusion process.
Methods such as textual inversion (TI) rely on tuning a token using a few images.
Relying on a pre-trained classifier allows the token to capture a broader distribution, corresponding
to a class, as opposed to specific features of the individuals in the given images. As seen below, TI-generated images often lack diversity and are prone to incorporating background features from a limited set of images. For reference, we also display SD's generated samples.
Lack of diversity In the Japanese spaniel class, TI generates a black-and-white dog due to limited colors in the images, causing "A statue of a Japanese spaniel" prompts to lose the statue texture.
Biased background In the beach wagon class, TI merges the road into the object, transforming both the car and the background from beach to road.

Our method has the ability to inverse the action of a classifier without access to its trained data. For example, we often observe changes in the background when optimizing for an object's class. Applying our method with ImageNet-trained classifier results in an image of a lobster on a plate given the phrase `American lobster.' Another example is the `horizontal bar' class, for which our method predominantly generates images containing athletes and a gym environment. We manually assessed ImageNet's training data by classifying 100 images from the `American lobster' and `horizontal bar' classes and determining whether they exhibit these features in the training data. For the `American lobster' class, 55% of the images featured a plate and the lobster in an edible form, and for the `horizontal bar' class, 95% of the images included an athlete performer.

@article{schwartz2023discriminative,
title = {Discriminative Class Tokens for Text-to-Image Diffusion Models},
author = {Schwartz, Idan and Sn{\ae}bjarnarson, V{\'e}steinn and Chefer, Hila and Cotterell, Ryan and Belongie, Serge and Wolf, Lior and Benaim, Sagie},
journal = {ICCV},
year = {2023}
}